¡Hola de nuevo! Como recordaréis, la semana pasada os hablé del código genético, el conjunto de reglas que utilizan los ribosomas para traducir el contenido del ARN mensajero en proteínas. Bien, pues hoy os quiero explicar cómo se descubrió este código genético y quiénes fueron las grandes figuras de la genética implicadas.
Para poneros en contexto, os diré que todo esto sucedió en la segunda mitad del siglo XX. En ese momento, James Watson, Francis Crick, Maurice Wilkins y Rosalind Franklin acababan de determinar la estructura helicoidal del ADN y el panorama científico estaba experimentando un desarrollo alucinante en el ámbito de la genética. Justo después, en 1956, Joe Hin Tjio y Albert Levan determinaron que las células humanas tienen un total de 46 cromosomas y, dos años después, Matthew Meselson y Franklin Stahl demostraron que la replicación del ADN es semiconservativa. En resumen, se estaban comenzando a conocer las reglas del “juego de la genética” y esto propiciaría la llegada de una “Era de la Genómica”, en la que nos encontramos actualmente.
Pero dejémonos de Genómica y volvamos un poco atrás en el tiempo. El descubrimiento de la estructura del ADN hizo que el panorama científico destinase muchos más esfuerzos e investigaciones a esta molécula tan curiosa. Y eso mismo les pasó a Severo Ochoa y a Marianne Grunberg-Manago, dos de las figuras “detonantes” del descubrimiento del código genético.
La polirribonucleótido-fosforilasa
Rondaban los años 50 cuando la bioquímica francesa de origen ruso Marianne Grunberg-Manago, que trabajaba en el laboratorio de Severo Ochoa, aisló un enzima bacteriano un tanto inusual. En ese entonces Ochoa y Grunberg-Manago pensaron que se trataba de una ARN-polimerasa, pero era algo incluso mejor, una polirribonucleótido-fosforilasa. La particularidad de este enzima es que, en unas condiciones concretas, es capaz de sintetizar cadenas de ARN in vitro sin necesidad de un molde de ADN. El descubrimiento de este enzima fue el inicio de una gran carrera para descubrir el código genético.
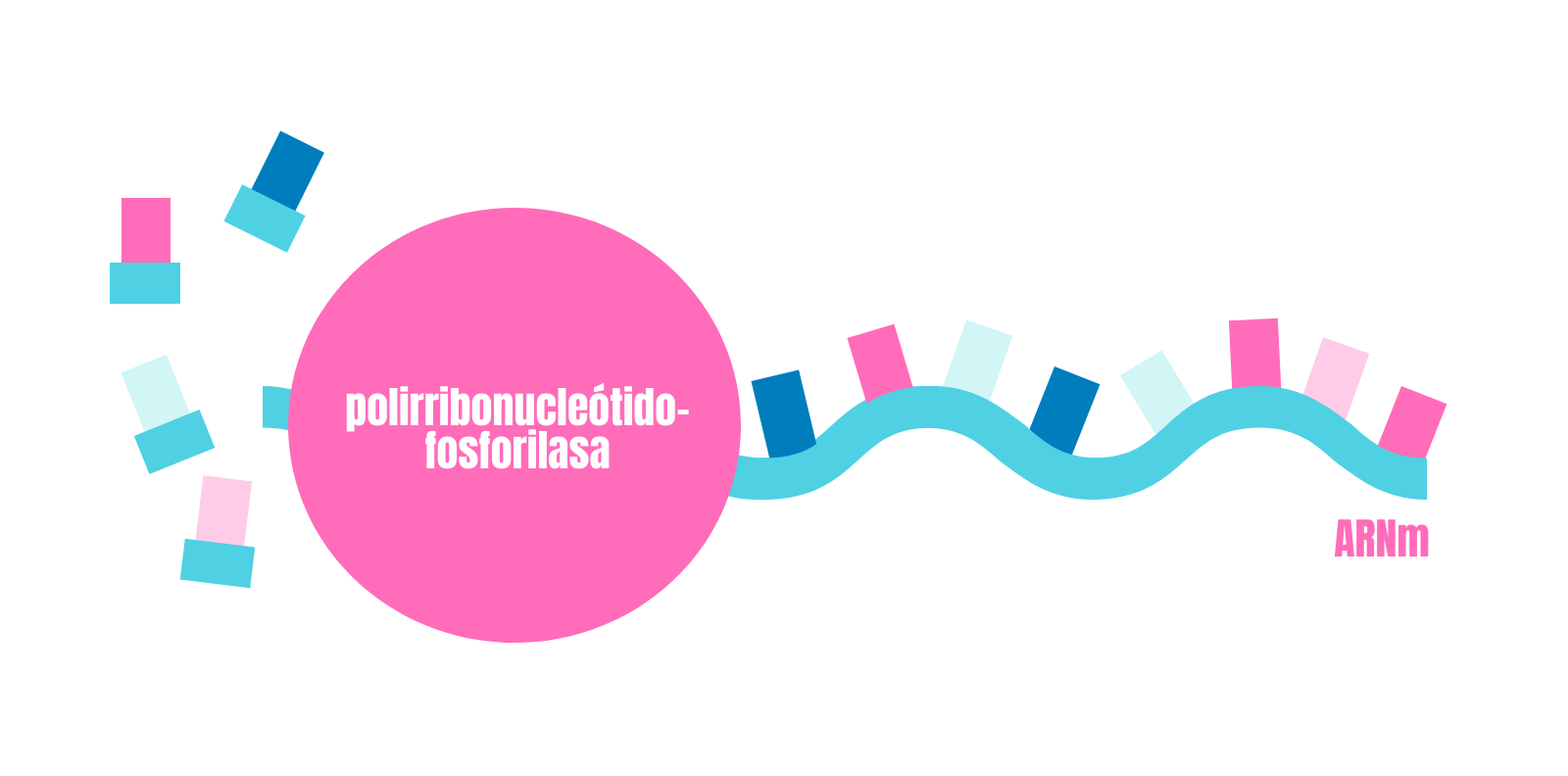
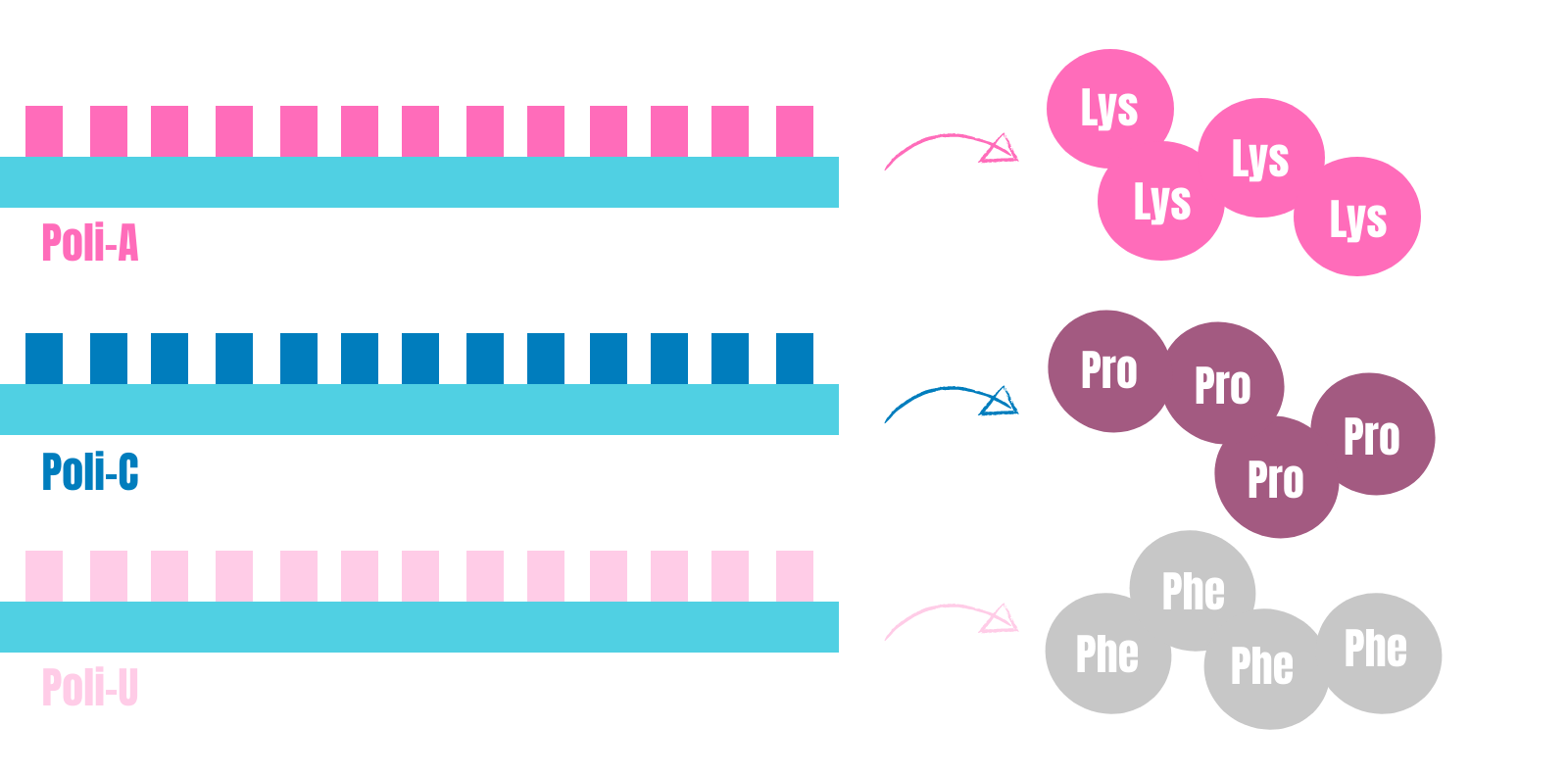
Gracias al descubrimiento de Grunberg-Manago, el equipo del estadounidense Marshall Warren Nirenberg y el alemán Johann Heinrich Matthaei logró sintetizar en 1961 cadenas de homopolímeros in vitro. Para que os hagáis una idea, un homopolímero en este caso sería una larga cadena formada solo por un tipo de nucleótido. Ellos sintetizaron cadenas poli-U y poli-C en concreto y las introdujeron en un sistema acelular capaz de traducir estas secuencias. De este modo, determinaron que el triplete UUU y el triplete CCC codifican para los aminoácidos fenilalanina y prolina respectivamente. Poco tiempo después, el equipo de Ochoa sintetizó el homopolímero Poli-A y determinó que el triplete AAA codifica para el aminoácido lisina.
Otros de los experimentos de los equipos de Ochoa y Niremberg utilizaron copolímeros, obtenidos de la actividad polirribonucleótido-fosforilasa en un medio con dos ribonucleótidos diferentes en distintas concentraciones. Por ejemplo, U y G en una concentración relativa de 5:1. De este modo, como la probabilidad de incorporar uno u otro nucleótido a la cadena era diferente, los equipos de investigadores podían “deducir” qué triplete correspondía a qué aminoácido, dependiendo de su concentración en la proteína resultante. De todos modos, estos experimentos no fueron muy útiles en el descubrimiento del código genético
La síntesis química
Mientras los equipos de Ochoa y Niremberg se “peleaban” con largas cadenas de polirribonucleóridos, otros grupos de investigadores se sumaron al estudio del código genético. Ese fue el caso del biólogo Har Gobind Khorana, que desarrolló y utilizó la técnica de síntesis química de ARN para generar polímeros de secuencia conocida. En concreto, Khorana y su equipo sintetizaron fragmentos Poli-AC, Poli.AG, Poli- UG y Poli-UC. Gracias a ello, lograron determinar lo siguiente:
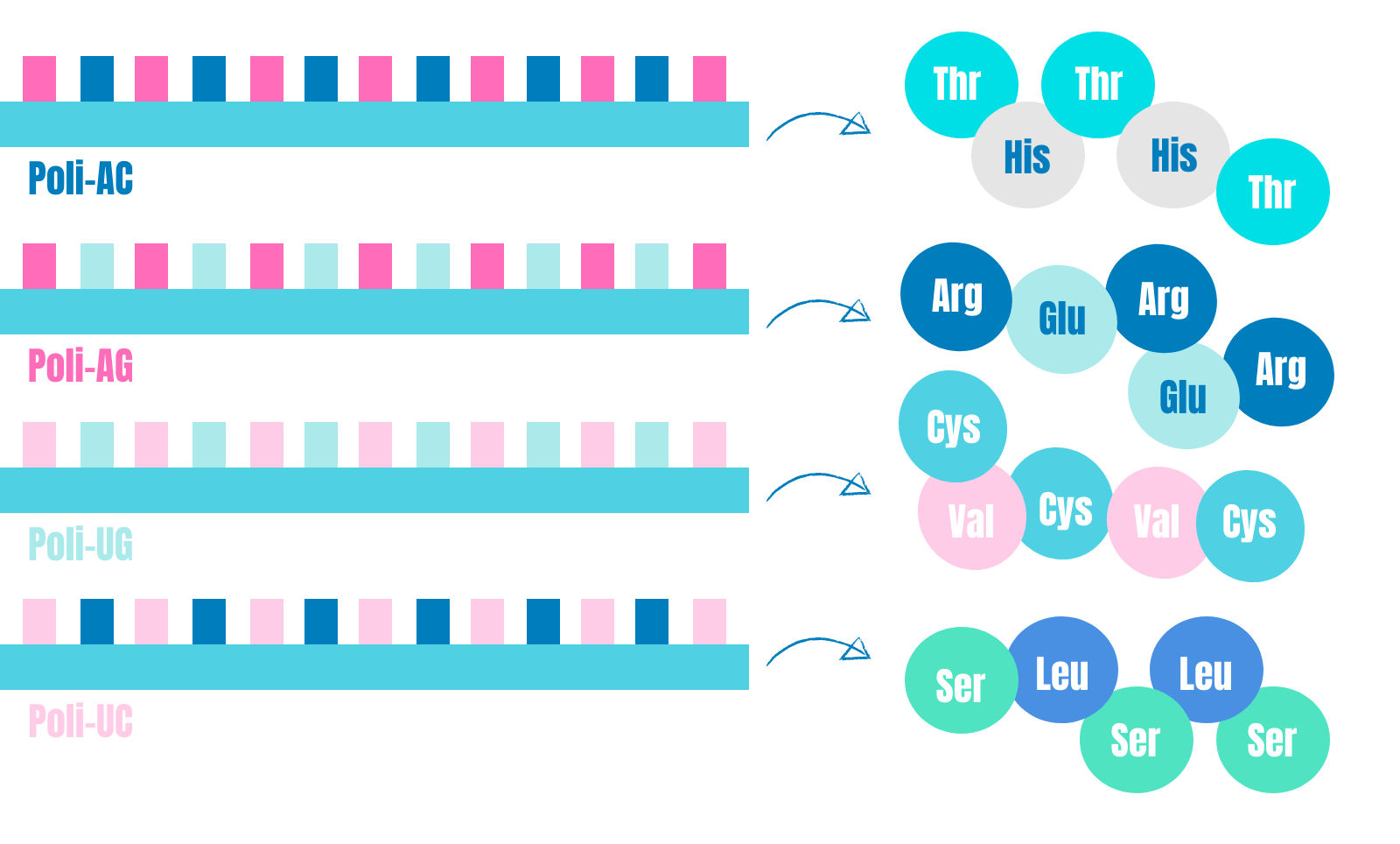
Con estos experimentos, Khorana y su equipo lograron describir qué aminoácido corresponde a los codones ACA, CAC, AGA, GAG, UGU, GUG, UCU y CUC. ¡Ya faltaba menos para descubrir el código genético completo!
El sprint final
Se aproximaba el cambio de década y los primeros experimentos de Khorana, Ochoa, Grunberg-Manago y el resto de investigadores únicamente habían dibujado lo que sería un esbozo del código genético. En este momento solo existían resultados claros para aproximadamente una veintena de combinaciones. ¿Qué pasó en los años 60 para que se lograran descubrir el resto de combinaciones?
Los equipos de Niremberg, Matthaei y Khorana continuaron trabajando para descifrar el código genético, pero esta vez con un enfoque algo diferente. En sus siguientes investigaciones, en lugar de analizar la cadena de aminoácidos que se traduce de un ARN conocido, estudiaron la especificidad con la que se une un triplete concreto con el ARN de transferencia con un aminoácido correspondiente. Recordemos que el ARN transferente es el que se encarga en los ribosomas de “detectar” el triplete del ARN mensajero y proporcionar el aminoácido correspondiente:
Para averiguar qué ARN transferente se une al triplete del ARN mensajero, lo que estos equipos hicieron fue repetir sus experimentos muchísimas veces y marcar radiactivamente solo un ARN transferente.
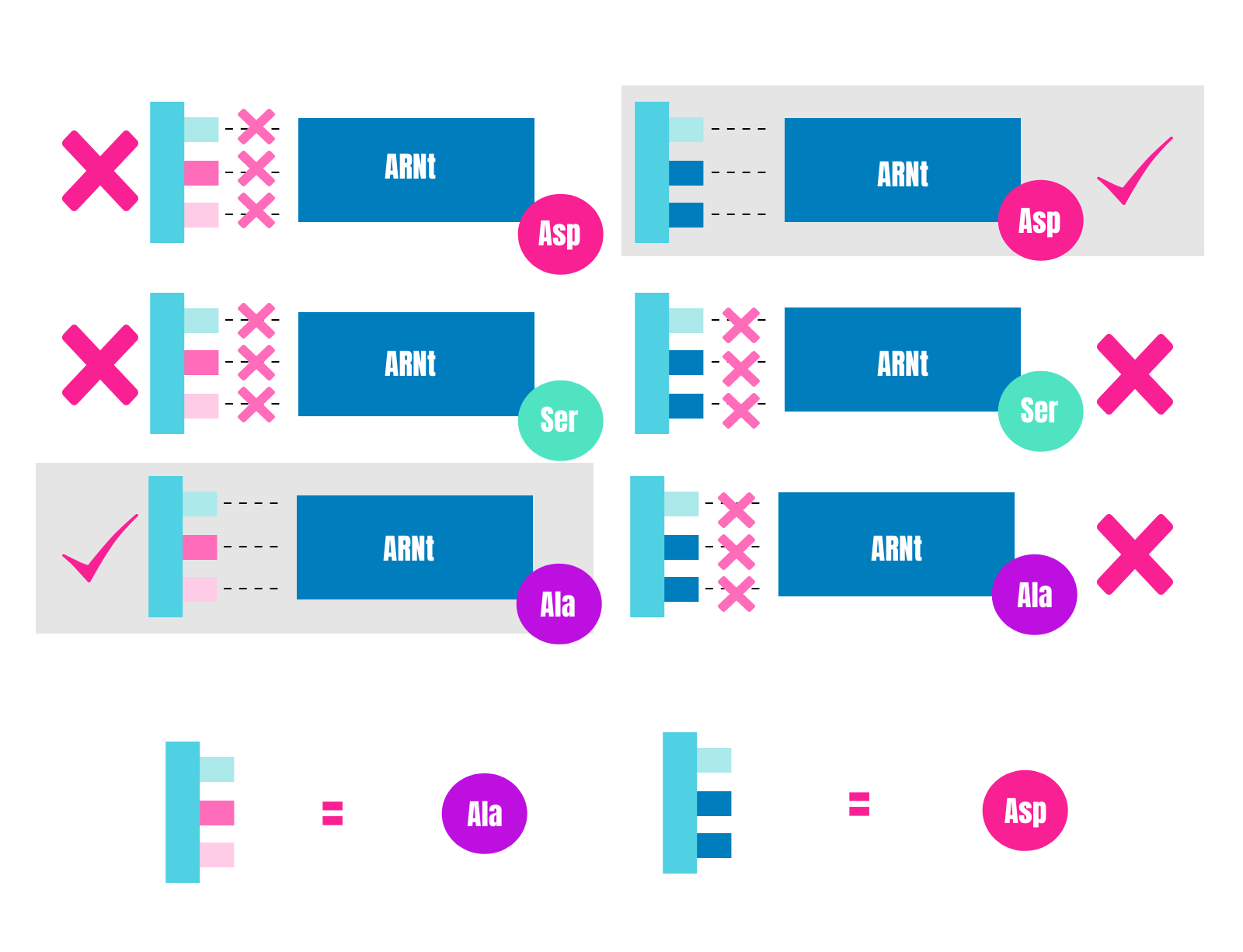
De este modo, los tres equipos lograron determinar los tripletes que faltaban del código genético que conocemos. ¡Menudo trabajazo!.

